What’s wrong with being Normal?
Normality is a red flag when it comes to matchmaking ratings (MMR)

Published by
Charlie Olson
on

Many games have MMR distributions similar to Overwatch 2. The key features are:
It’s nearly normal
The median is near zero
These might seem like expected and desirable properties of an MMR distribution, but there are two problems:
The majority of players have negative MMR. By itself, this would only be a minor flaw with an easy fix.
The symmetrical shape of the distribution is not an accurate model of player skill (probably not even close). This is the big problem.
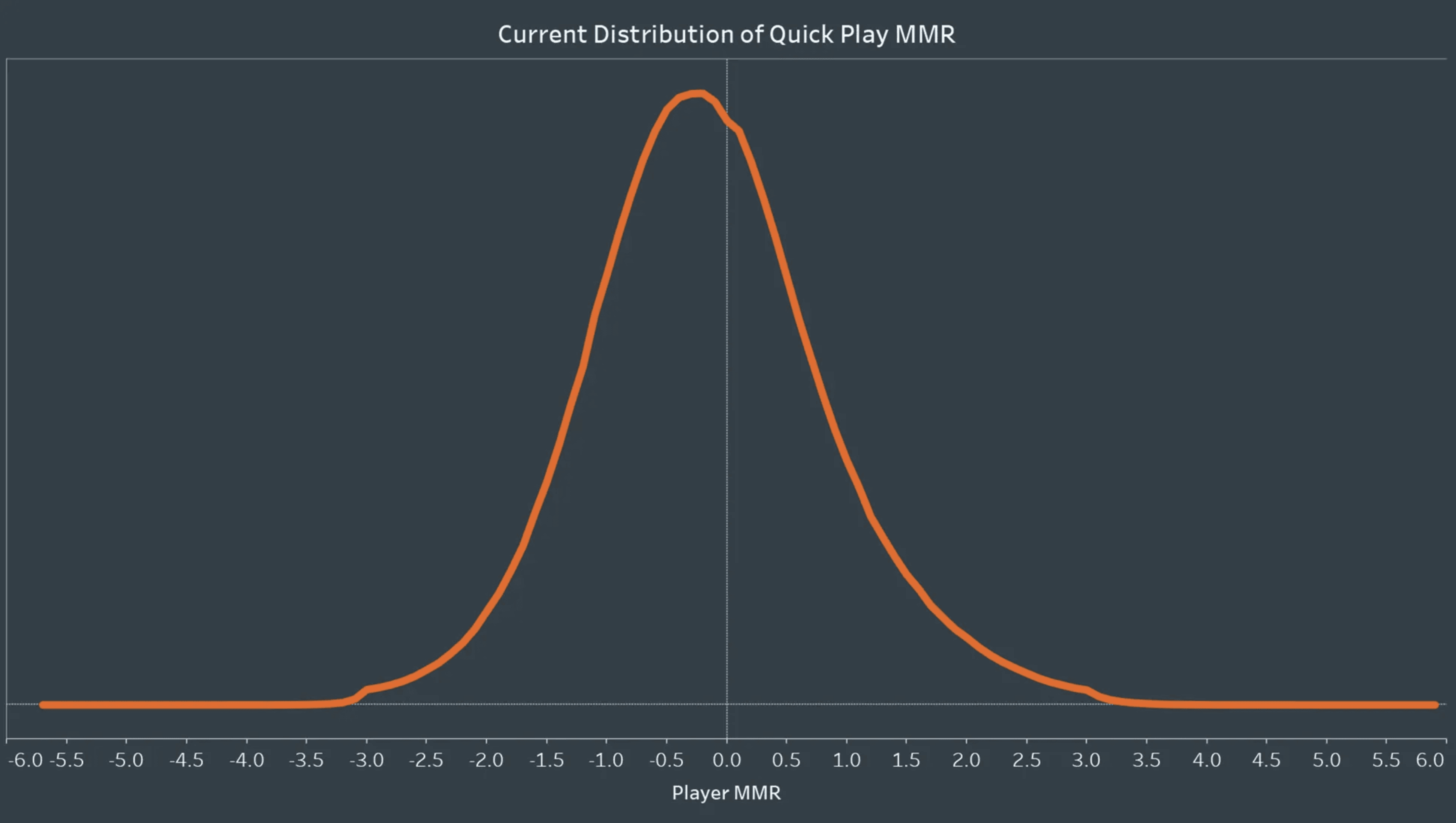
Overwatch MMR distribution (probably similar for the Hidden MMR in Ranked)
Negative MMR should be rare
Easy problem first: negative MMR doesn’t make sense in an objective-based game like Overwatch.
“But MMR is relative”, you might say. “Only the difference in MMR matters; any translation is canceled out.”
Right? In theory it should make no difference whether the mean MMR is -0.5, 2.0, or 1000. Furthermore, teams are often modeled as the sum of player MMRs. So, again, the difference in team MMRs should be the same regardless of any offset in the distribution.
However, every online multiplayer game is affected by leavers: players who quit matches early — whether intentionally, or due to network problems — and leave their teammates to carry on shorthanded.
If you want to give players fair and accurate MMR updates, your team model needs to account for lopsided teams. A game might start as 4 v 4, but if one player is disconnected after playing 75% of the match, it’s ultimately 4 v 3.75.
To demonstrate the point, in the case of a typical 3 v 3 match, translating MMR indeed doesn’t matter. The difference in team MMRs stays the same, which means the expected outcome stays the same, regardless of MMR offset:
# "Overwatch" MMRsteam_a_mmr = [2, 0, -1]team_b_mmr = [0, 0, 0]sum(team_a_mmr) - sum(team_b_mmr) => 1 # Team A is expected to win
# Corrected MMRs. Same as before, but offset by +3team_a_mmr = [5, 3, 2]team_b_mmr = [3, 3, 3]sum(team_a_mmr) - sum(team_b_mmr) => 1 # Team A is still expected to win
But in a lopsided match, like 2 v 3, correcting the MMR will flip the predicted outcomes for these teams:
# "Overwatch" MMRs, missing one playerteam_a_mmr = [2, 0]team_b_mmr = [0, 0, 0]sum(team_a_mmr) - sum(team_b_mmr) => 2 # Team A is expected to win shorthanded!
# Corrected MMRs +3, missing the same playerteam_a_mmr = [5, 3]team_b_mmr = [3, 3, 3]sum(team_a_mmr) - sum(team_b_mmr) => -1 # Team B is expected to win (correctly)
With negative MMR, like in Overwatch, we would have predicted the shorthanded team to win… by more than if they were full strength! So, if they actually lose, they will lose a lot of MMR, or if they manage a shorthanded victory, they will receive very little MMR in return, which is probably the opposite of how it should be.
Conversely, the corrected MMR values predicted the shorthanded team to lose, so if they lose as-expected, it’s not a big change in MMR, and if they win, it’s a big gain.
There are of course other hacks to deal with leavers, but having a good team model will minimize the exploit vectors. Using “no one” as the reference point for zero MMR also gives developers a better idea of the real distribution of skill in their game.
In some sports, higher rates of negative MMR indeed make sense — where a low-skill teammate is worse than no teammate at all (volleyball, beer pong, TDM, etc) — but it should be rare in most objective-based game modes.
Skill isn’t symmetrical
This is the big problem. There simply shouldn’t be a long skinny tail on the left side of the MMR distribution. Unless, for every pro player at +3.0 MMR, there is a bizarro anti-pro grinding 14 hours a day to become the world’s worst -3.0 MMR player?
Not likely. The mechanics of the game don’t even allow players to be prodigiously bad, much less in equal numbers to good players. The real skill distribution probably looks more like this:
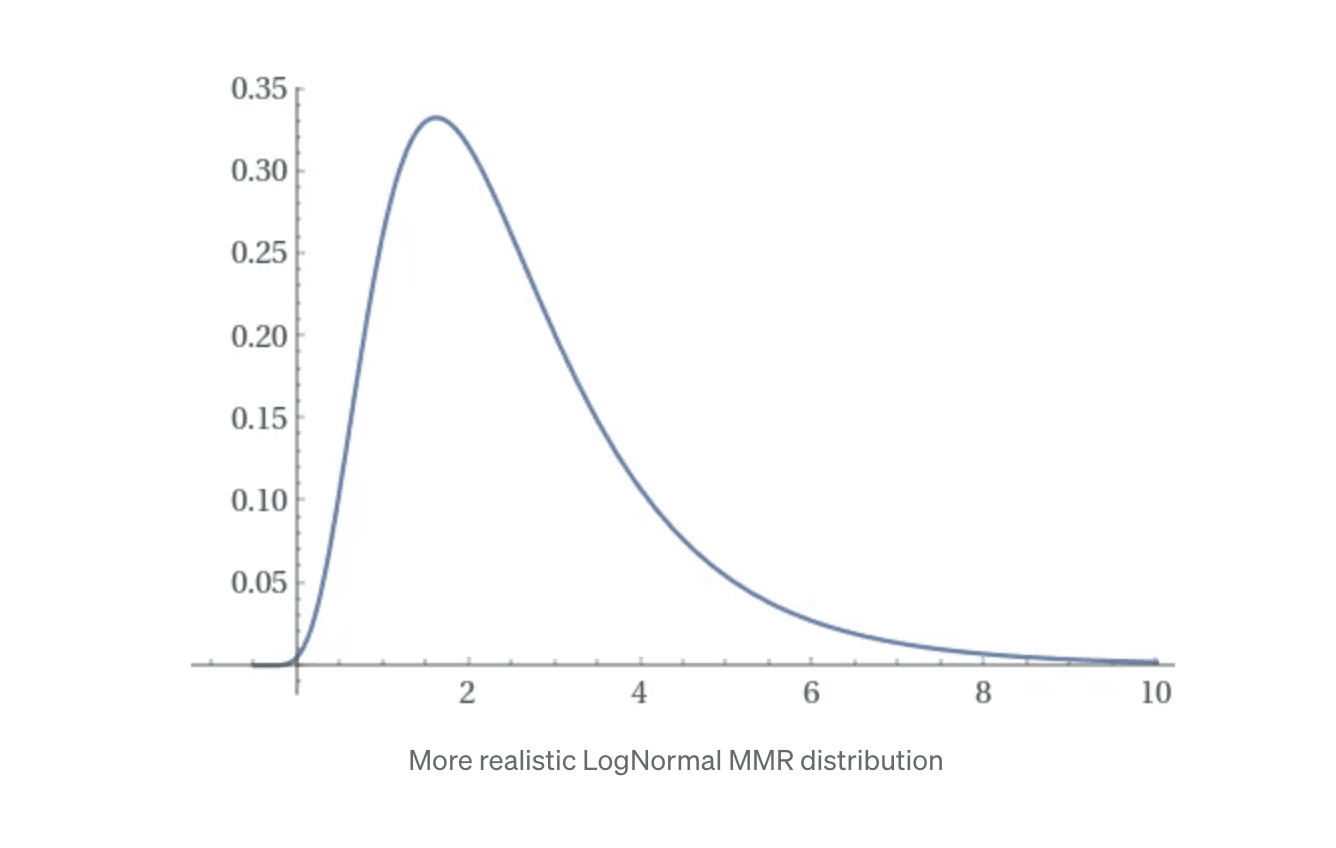
*The tiny negative tail above consists of griefers who find creative ways to kill their own teammates (in a game that doesn’t have friendly-fire enabled).
Why is the mismatch between the real skill and MMR distributions problematic? Without direct access to Overwatch data, it won’t be possible to show conclusively, but we can still look at it mathematically (and make some testable predictions).
The mismatch means MMR will have different meanings for different skill groups, because the population density will compress or expand differently across the distribution.
Intuitively, if a lot of players are concentrated in a narrow band of skill, but that cohort maps to a long skinny tail on the MMR distribution, then MMR is going to become diluted for those players. MMR will feel random and meaningless. There will be a large separation of MMR between players of similar skill. MMR updates will be coarse and noisy (which is ok for casual MMR, but not for ranked).
That’s a lot of conjecture, so here’s some explanation. Below are hypothetical distributions of skill (purple) and MMR (yellow):
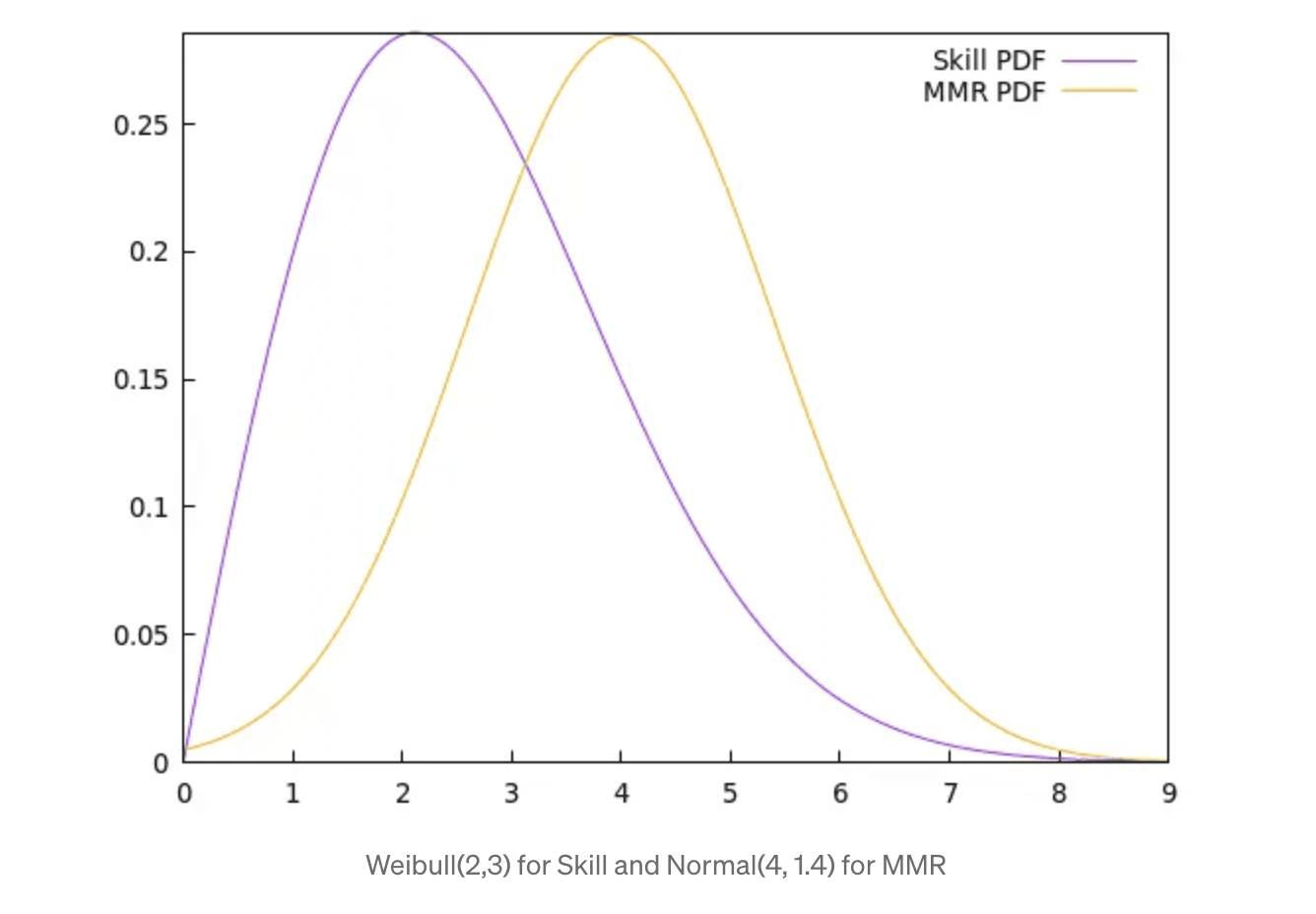
The compression or expansion of the skill-to-MMR population density can be calculated from the ratio of the PDFs mapped by percentile. More specifically, by the log of the ratios of the PDFs (with some added finesse to avoid near-zero denominators), which I’m calling the “smush index”:

= smush index of transforming A → B
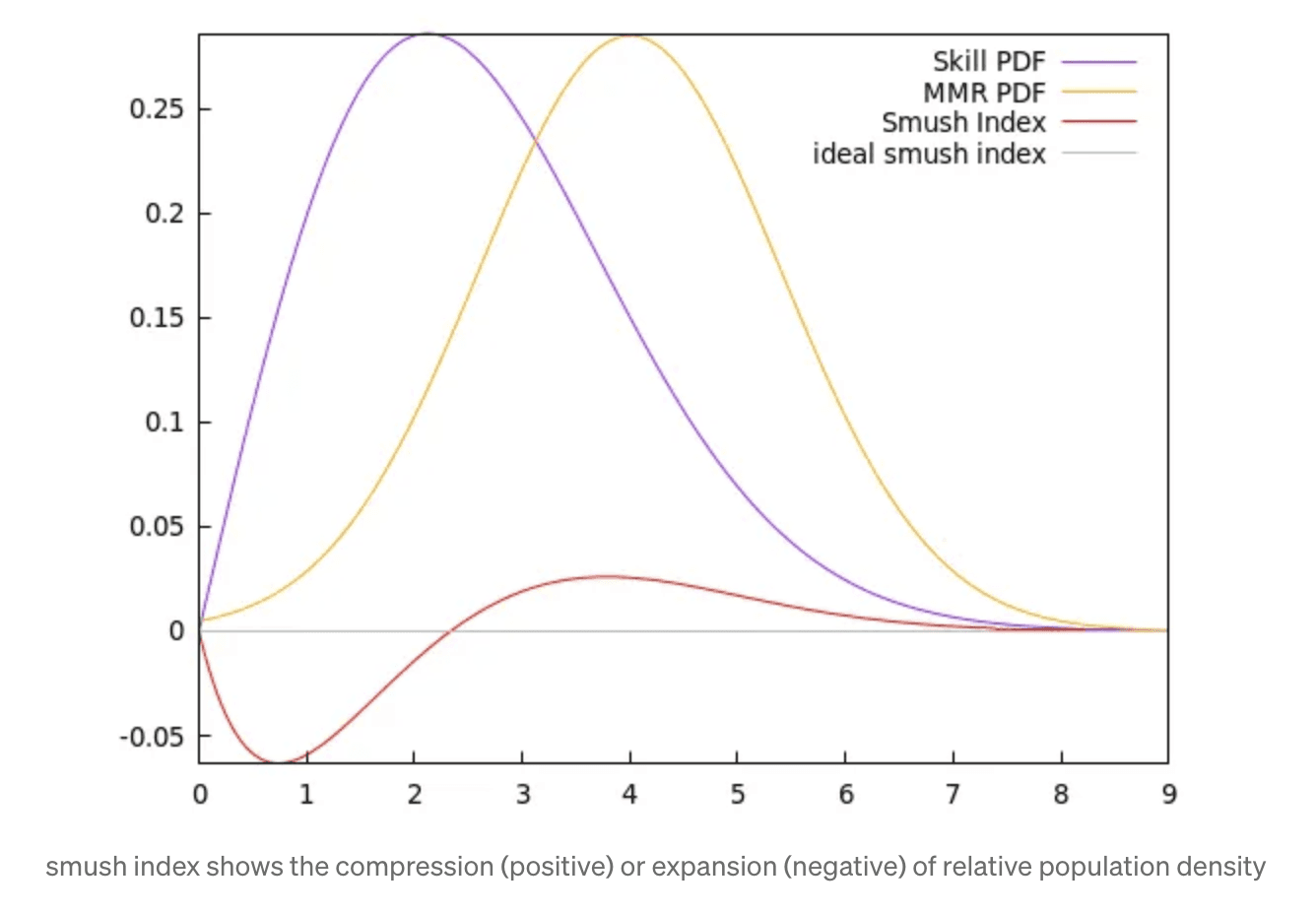
In order to compare distributions better, let’s convert the x axis to quantiles (rather than skill deviations):
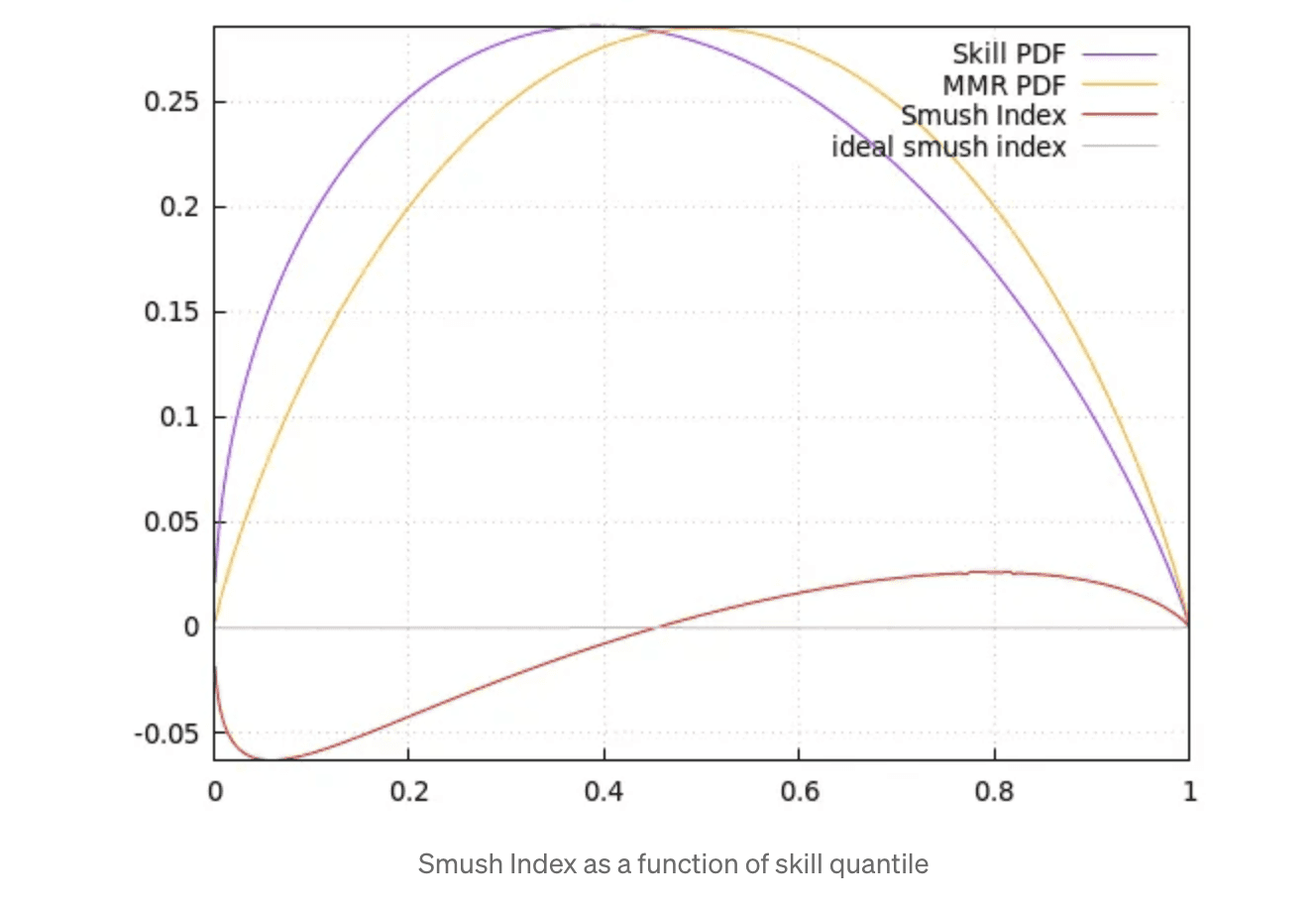
Full disclosure: I’m not a mathematician, I’m just a simple gameplay programmer. There is probably better academic vernacular to describe transformations between distributions than “smush index”, but I don’t know what it is.
What this quantifies though, is the MMR expansion (negative smush) for below-average players — everyone below the 45th skill percentile goes from a high density of skill to a low density of MMR.
These below-average players would have a baffling experience in a ranked mode, because their MMR would meander almost randomly over a large range.
In casual modes, it’s mostly ok, since everyone is close in skill, and there’s a low chance of encountering a high-skill player, but it would also increase the appeal of smurfing, for those same reasons.
Meanwhile, mid-to-high-skill players won’t get enough MMR separation. Players near the 80th percentile encounter peak compression. A small increase in MMR will lead to disproportionately stronger opponents. So, these players could be prone to a “whiplash” effect (extreme oscillation between difficult and easy matches). Hitting this wall could also increase the appeal of smurfing.
If the model holds up, it leads to some testable hypotheses:
Highest personal MMR variance: <20th percentile
Less prediction accuracy (as a function of MMR gap) below 45th percentile than above
Lowest prediction accuracy: <20th percentile
Highest prediction accuracy: ~80th percentile
Most whiplash (highest personal-variance in performance but lowest personal-variance in MMR): ~80th percentile
More reasons why skill is unlikely to be symmetrical
As far as I know, normal distributions tend to describe attributes within temporal segments, like height within an age group, or player skill after 1000 hours, or skill potential after infinite time, but rarely describe quantities across temporal segments.
In games, if skill is strongly correlated with time spent playing or training then the skill distribution will be heavily influenced by the distribution of total play time. So, a more realistic skill distribution might simply resemble age in a population:
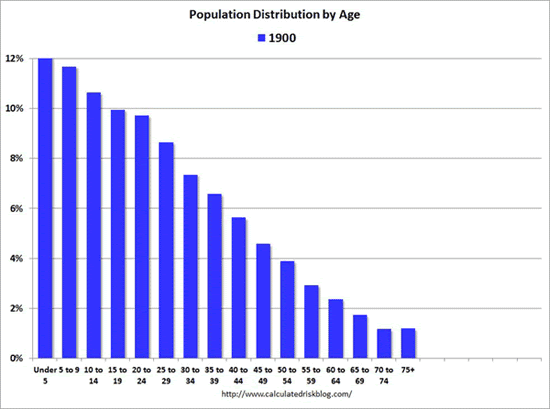
US Population Distribution by Age
In the case of games, not everyone “ages” at the same rate. So, even if relatively few n00bs are being born in this analogy, the bottom-heavy distribution of play-time-per-day could have a similar skewing effect.
In games with very steep learning curves and high skill ceilings, a realistic skill distribution might even be close to exponential (as a product of player acquisition * play-time-per-day * retention * talent). This is consistent with Street Fighter V’s MMR distribution:

Conclusion
Normal distributions of MMR are major sus, and negative MMR values low key throw hands with your team-modeling.
Zero MMR can be tuned directly from data, by looking at actual team win rates vs predicted win rates in asymmetrical matches, and adjusting the MMR offset until they fit better. The MMR offset can be worked invisibly into the math if necessary, without affecting the current MMR values.
A symmetrical distribution is a deeper symptom though, and it depends on the game whether or not it’s acceptable. If the reason for the symmetry is because the game is using Elo or TrueSkill under the hood, then there are even bigger problems! But that’s a topic for another article.
If you're a dev with matchmaking rating questions, join our Discord community.
Appendix
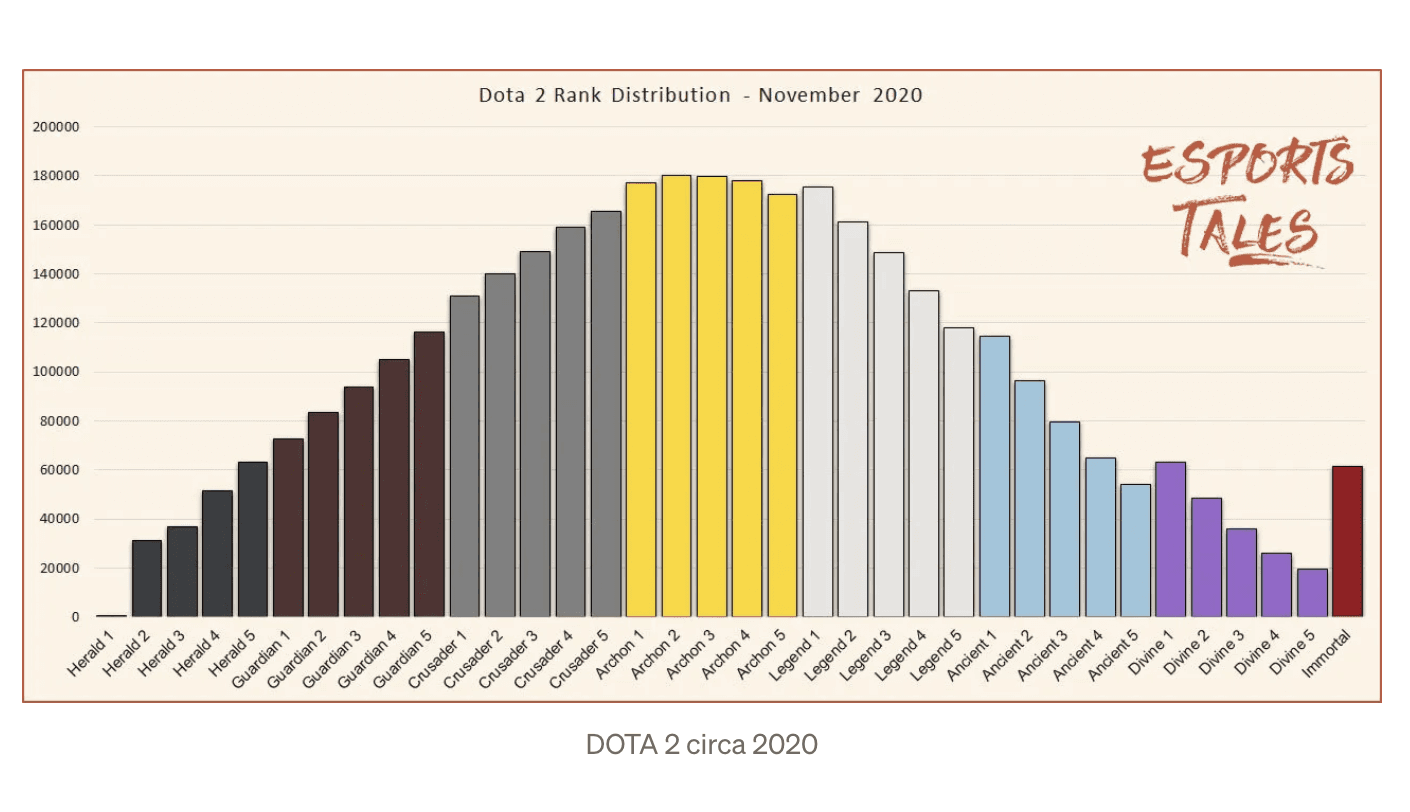
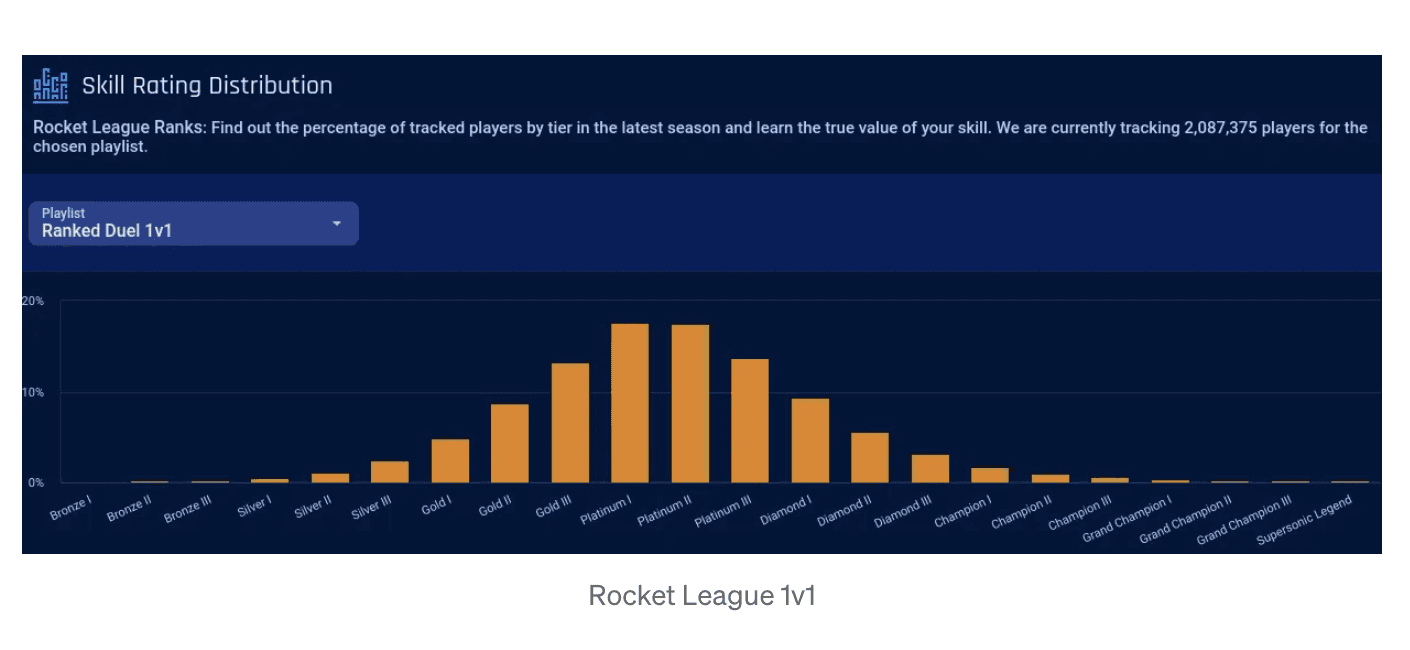
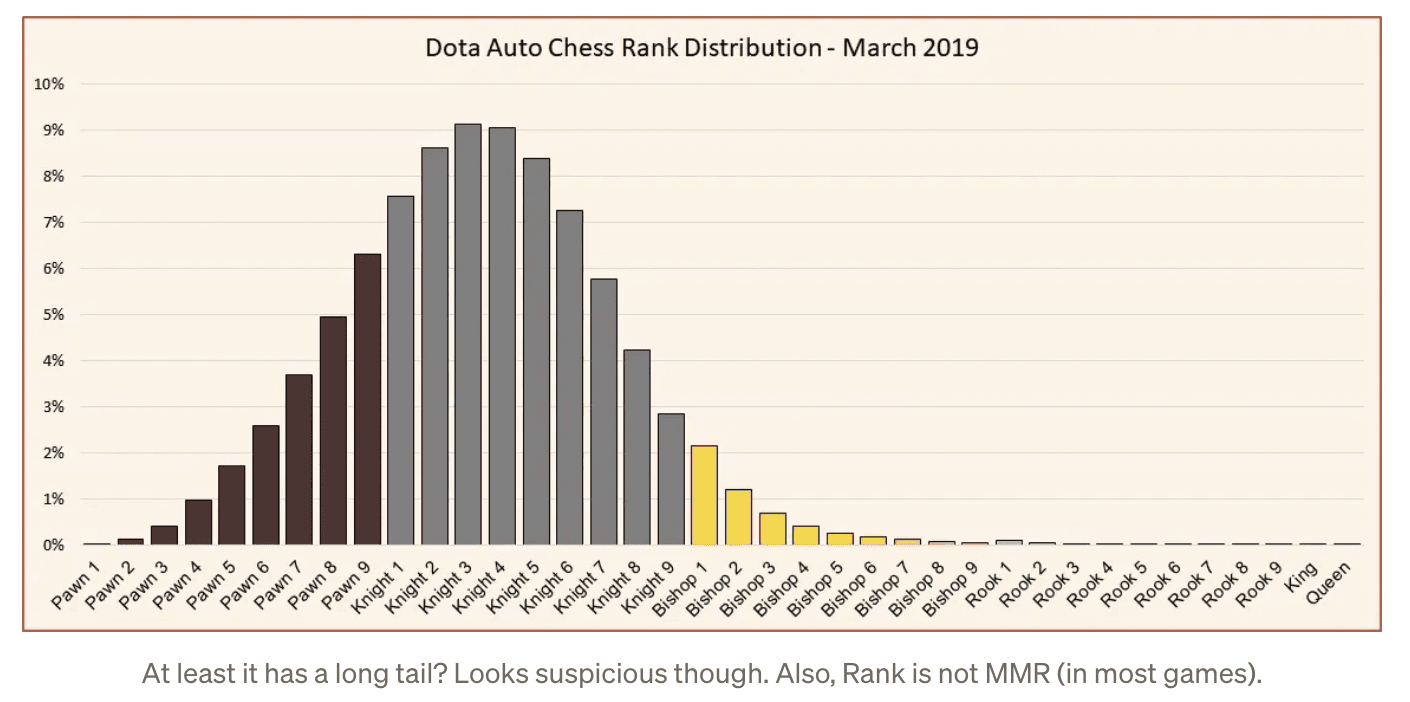
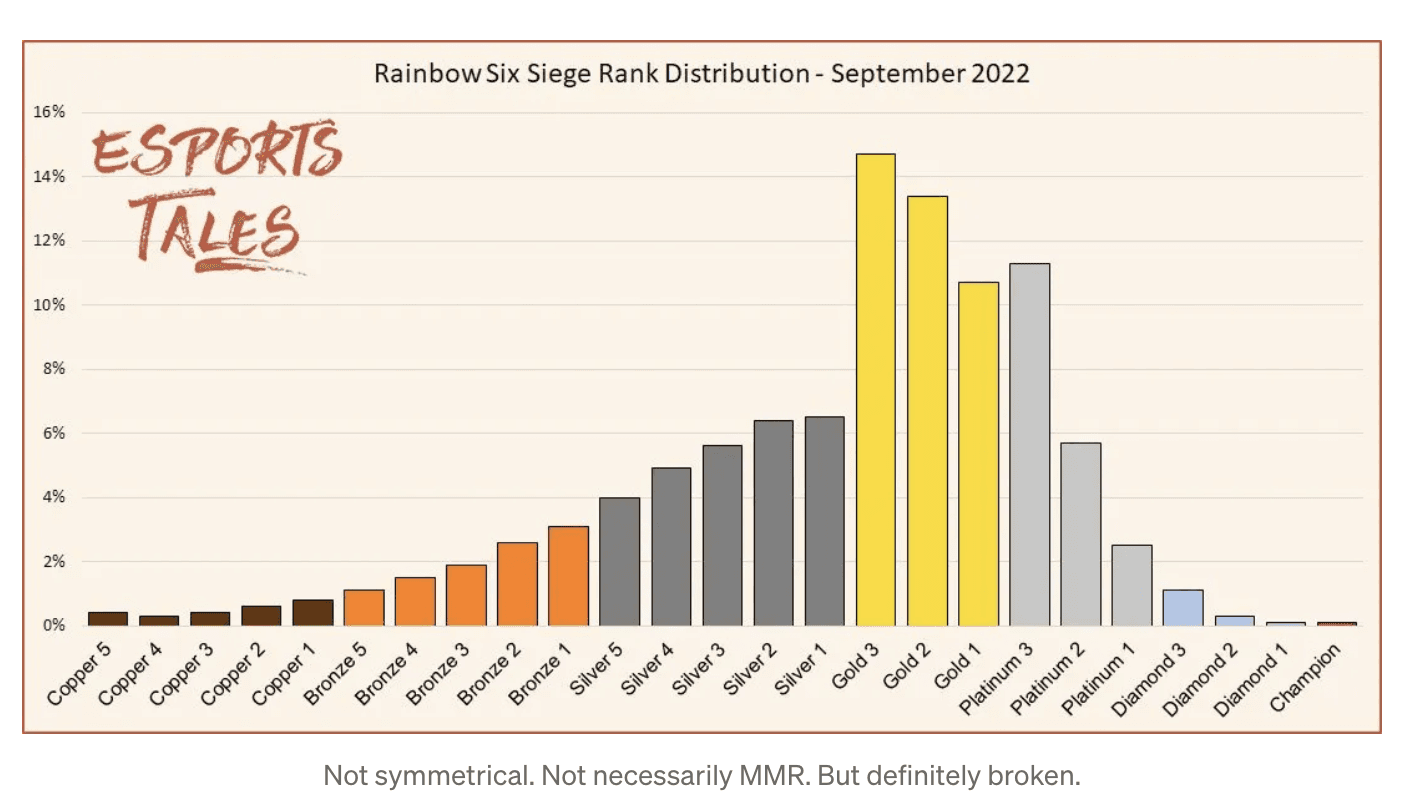
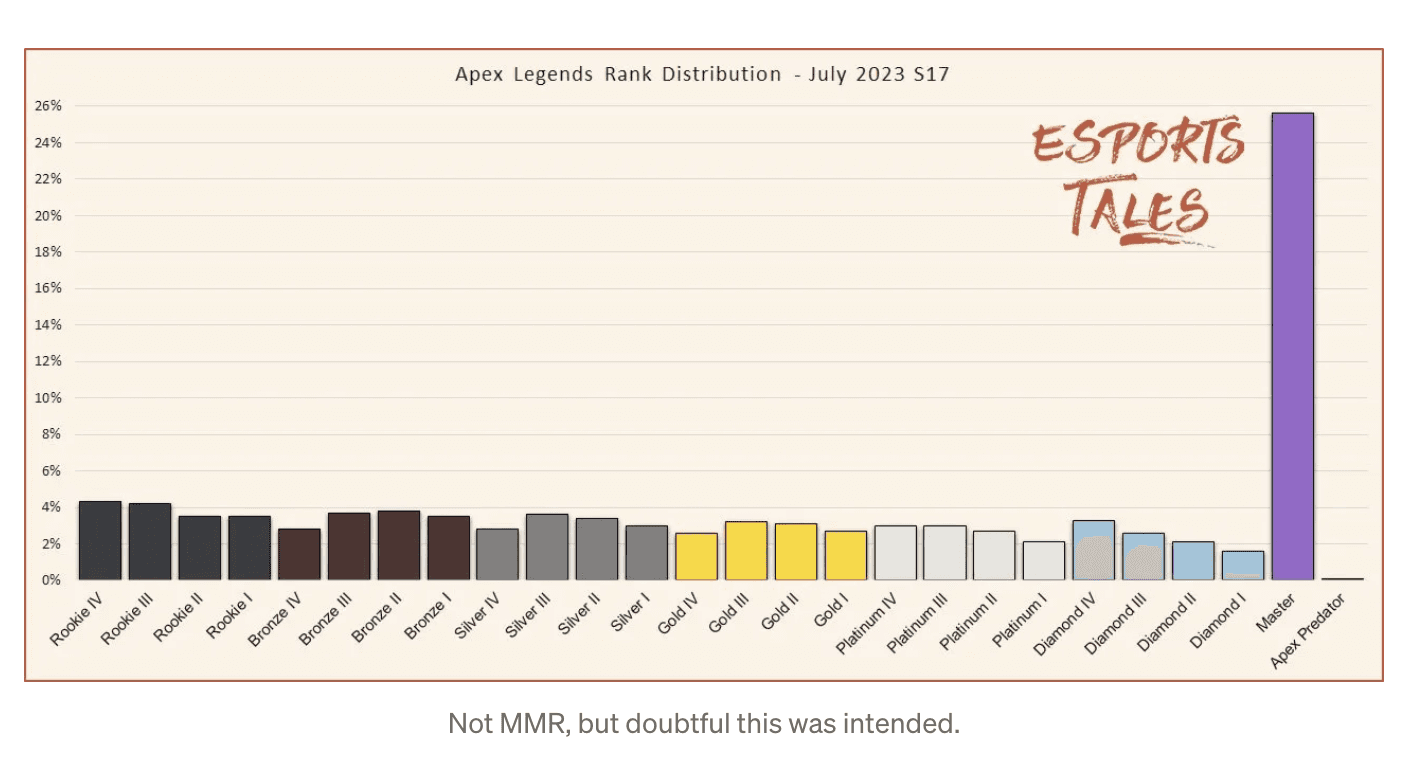
Some games with normal Rank distributions (and some that are just weird). Not necessarily corresponding to MMR: